傾向スコアについてもうちょっと考えてみる。
この記事は異世界行ったら本気だすぴょこりんクラスタ Advent Calendar 2021のためにかきました。
はじめに
昨日の記事では傾向スコアというものを導入し、傾向スコアマッチングでバイアスを取り除いて効果検証的なことをしてみました。これについてもうちょい考えてみましょう、というのが今日のコンセプトです。
今日扱うダミーデータちゃん
効果検証にあたり、介入があったサンプル(z=0)となかったサンプル(z=1)の分布に違いが無ければ簡単に効果検証ができるのですが、例えば特定層にのみ介入をしているため、バイアスが生じてしまう、という話でした。
今日取り扱うのは以下のような散布図です。

ガウス分布ですね。そして全ての成分の絶対値が0.05未満のものに対して、6割の確率で介入が行われる(z=1)、という感じのデータを生成しています。
ちょうどオレンジの矩形の部分がそれに該当しています。
この矩形の中でだけ介入をするなんてことをせずに、ただランダムに介入していればバイアスは生じなかった。でもそういうことをしてしまったという想定です。
生成のコードは以下。
n_sample=2000
m_1=np.random.normal(0,0.01,2)
v_1=invwishart(2,np.array([0.01,0.01])).rvs()
sample=multivariate_normal(m_1,v_1).rvs(n_sample)
z=[]
for s in sample:
if np.abs(s[0])<0.05 and np.abs(s[1])<0.05 and np.random.random()>0.4:
z.append(1)
else:
z.append(0)
sample_a=np.array([i[0] for i in zip(sample,z) if i[1]==0])
sample_b=np.array([i[0] for i in zip(sample,z) if i[1]==1])
結果関数
y=50-100*(x1)2-60*(x2)2+20*z
得られる報酬などに対応する結果の関数に今回は二次関数を選んでみます。zにかかる係数、真の介入効果は20です。これをこの数式の知識無しに推定したいというのが問題設定。
早速前回同様z=1のサンプルとz=0のサンプルの平均の差を取ってバイアス盛り盛りな効果測定をしてみます。
y_a=50-100*sample_a[:,0]**2-60*sample_a[:,1]**2 y_b=50-100*sample_b[:,0]**2-60*sample_b[:,1]**2+20 np.mean(y_b)-np.mean(y_a) # 34.19147100834354
ばっちりバイアス盛り盛りですね。前述の二次関数は原点を頂点とする放物線なので、z=1のサンプルはそもそもyが介入の有無にかかわらず大きな値を取りがちなので、その分のバイアスがのっかっていると解釈できます。
傾向スコアマッチング・・・あれ?
先日同様の感じで傾向スコアマッチングでバイアスを除去してやりましょう。
で、結果として出てきた数値が35.92、除去できてないどころか悪化している。
コードは以下。
from sklearn.linear_model import LogisticRegression
n_sample_a=len(sample_a)
n_sample_b=len(sample_b)
z=np.concatenate([np.zeros(n_sample_a),np.ones(n_sample_b)],0)
samples=np.concatenate([sample_a,sample_b],0)
classifier=LogisticRegression()
classifier.fit(samples,z)
propensity_scores=classifier.predict_proba(samples)
score_a=propensity_scores[:n_sample_a,1]
score_b=propensity_scores[n_sample_a:,1]
expect2=0
for y,score in zip(y_b,score_b):
expect2+=(y-y_a[np.argmin([np.abs(score-j) for j in score_a])])/len(score_b)
print(expect2)
# 35.924936989656075
傾向スコアのフィッティングがイマイチ
傾向スコアは介入されやすさを表す0~1の値でした。これを推定するためにロジスティック回帰を用いたのでした。
ロジスティック回帰は皆様ご存じの通り、まっすぐな識別境界しか引くことが出来ません。先ほどの散布図に対して、まっすぐな線を一本引いて青とオレンジを分離しろと言われてるようなものですね。
試しにどんな識別境界引いたか見てみます。
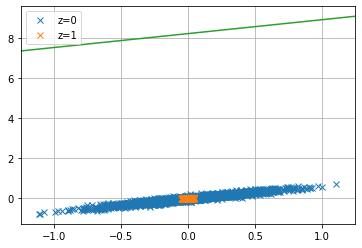
緑色の線がz=0とz=1の識別境界になります。はい、諦めてますねこれは。ほとんどの値がz=0なのだから全部0って返すクソ雑識別器になってます。
これでは傾向スコアも信用できないものになっているでしょう。先日と同様傾向スコアのヒストグラムも見てみましょう。
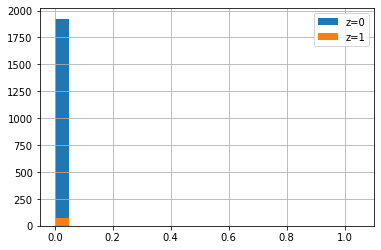
まぁ想像の通りかと思います。ほぼ0に張り付いていますね。これでは傾向スコアにまるで情報が無い。バイアスも減らないわけです。
別の識別器で傾向スコアを算出する
問題はzが1であるか0であるかの傾向をうまくモデリングできないことなので、非線形な識別境界に対応できる学習器で傾向スコアを算出してあげれば良さそうです。
ここでは手っ取り早くrbfカーネルのSVMを使ってしまいましょう。SVMのpredict_proba、それらしい値を出す方法はありそうな気はしつつ、実際どう計算されているのか1ミリも理解しないまま放置している気もしつつ、便利なので使っていて良くない。
SVMベースで傾向スコアを算出、傾向スコアマッチングをしてみるとほぼ20になりました。
from sklearn.svm import SVC # 書き換えた
n_sample_a=len(sample_a)
n_sample_b=len(sample_b)
z=np.concatenate([np.zeros(n_sample_a),np.ones(n_sample_b)],0)
samples=np.concatenate([sample_a,sample_b],0)
classifier=SVC(probability=True) # 書き換えた
classifier.fit(samples,z) # 書き換えた
propensity_scores=classifier.predict_proba(samples)
score_a=propensity_scores[:n_sample_a,1]
score_b=propensity_scores[n_sample_a:,1]
expect2=0
for y,score in zip(y_b,score_b):
expect2+=(y-y_a[np.argmin([np.abs(score-j) for j in score_a])])/len(score_b)
print(expect2)
# 19.998287672903757
ヒストグラムは以下のような感じ。介入されたサンプル (z=1) は数が少ないので見にくいですが、まぁまぁ分離できてるのが確認できると思います。
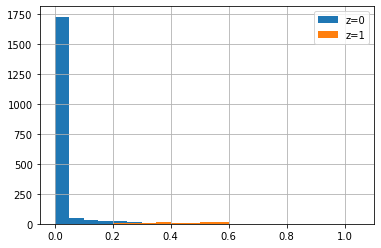
最大値が冒頭のサンプリング時に決め打ちした介入するかどうかの割合である0.6 (6割) あたりにへばりついてるのも直観にあっていて気持ち良いですね。
SVMの識別境界書くのはちょっと大変なので、傾向スコアのヒートマップと先ほどの散布図を重ねてみましょう。ヒートマップの明るい部分とオレンジの点群の位置が一致していればよくフィッティングしていると言ってよいかと思います。

なかなか悪くないんじゃないでしょうか。
今回のようなケースでは真の識別境界は矩形になるので、決定木なんかを使ってもよかったかもしれませんねーとか思う一方、決定木だと傾向スコアが一定になりがちであんまり近くなくても矩形の中ならマッチングしちゃうみたいなことも起こりそうですね。
傾向スコアマッチング、近い傾向スコアだとほぼ近傍の点とマッチングすることになるという暗黙の了解のもと成立しているような気がしていて、山や谷を多く持つ複雑な報酬系、要は遠方にも近い傾向スコアの点がたくさん存在するような場合は、(たとえ傾向スコアを上手にモデリングできたとしても、)あんまり機能しないのではないかーという気がしました。この辺ちゃんと理論知った上でやった方が良いかもなーと思いつつ。
おわりに
というわけで傾向スコアを扱うにあたって、ロジスティック回帰じゃうまくいかなさそうだなーというケースのダミーデータで試してみて、実際うまくいかないことと、代わりにSVM使ったらうまくいったことを確認しました。
多分そうなるだろうなーと思ったことがきちんとそうなると気持ち良いですね。おしまい。